Titanic Overview
This project aims to predict the survival of passengers on the Titanic based on various features such as age, sex, class, and fare. The project uses machine learning algorithms to train models on the Titanic dataset and evaluate their performance.
Contents
gender_submission.csv: A sample submission file in the correct format.README.md: This file, providing an overview of the project.test.csv: The test dataset used for making predictions.Titanic_cross_validation.ipynb: Jupyter notebook for cross-validation and model evaluation.Titanic_model.ipynb: Jupyter notebook for building and training the predictive model.train.csv: The training dataset used to build the model.
Models
The project uses several machine learning algorithms, including:
- Decision Tree Classifier
- Linear Support Vector Machine (SVM)
- Gradient Boosting Classifier
- K-Nearest Neighbors (KNN)
- Naive Bayes
- Logistic Regression
Performance Metrics
The project evaluates the performance of each model using accuracy, precision, recall, and F1-score.
Requirements
- Python 3.x
- Jupyter Notebook
- scikit-learn
- pandas
- numpy
- matplotlib
- seaborn
Implementation
EDA, Feature engineering and Model Building.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
train = pd.read_csv('titanic/train.csv')
test = pd.read_csv('titanic/test.csv')
train['train_test'] = 1
test['train_test'] = 0
test['Survived'] = np.NaN
df = pd.concat([train,test])
Analysis
df.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | train_test | |
|---|---|---|---|---|---|---|---|---|
| count | 1309.000000 | 891.000000 | 1309.000000 | 1046.000000 | 1309.000000 | 1309.000000 | 1308.000000 | 1309.000000 |
| mean | 655.000000 | 0.383838 | 2.294882 | 29.881138 | 0.498854 | 0.385027 | 33.295479 | 0.680672 |
| std | 378.020061 | 0.486592 | 0.837836 | 14.413493 | 1.041658 | 0.865560 | 51.758668 | 0.466394 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.170000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 328.000000 | 0.000000 | 2.000000 | 21.000000 | 0.000000 | 0.000000 | 7.895800 | 0.000000 |
| 50% | 655.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 | 1.000000 |
| 75% | 982.000000 | 1.000000 | 3.000000 | 39.000000 | 1.000000 | 0.000000 | 31.275000 | 1.000000 |
| max | 1309.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 9.000000 | 512.329200 | 1.000000 |
df.dtypes
PassengerId int64
Survived float64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
train_test int64
dtype: object
numeric = train.select_dtypes(exclude='object')
numeric.columns
Index(['PassengerId', 'Survived', 'Pclass', 'Age', 'SibSp', 'Parch', 'Fare',
'train_test'],
dtype='object')
#correlation with prediction/target var
correlation = abs(numeric.corr()*100)
correlation[['Survived']].sort_values(['Survived'], ascending=False)
| Survived | |
|---|---|
| Survived | 100.000000 |
| Pclass | 33.848104 |
| Fare | 25.730652 |
| Parch | 8.162941 |
| Age | 7.722109 |
| SibSp | 3.532250 |
| PassengerId | 0.500666 |
| train_test | NaN |
plt.figure(figsize=(8,6))
sns.heatmap(correlation, mask=correlation<10, cmap='Blues', vmin=10, linewidths=.5, linecolor='k')
<AxesSubplot:>
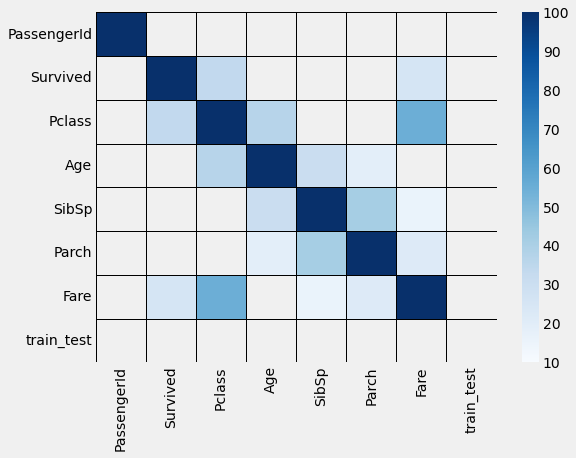
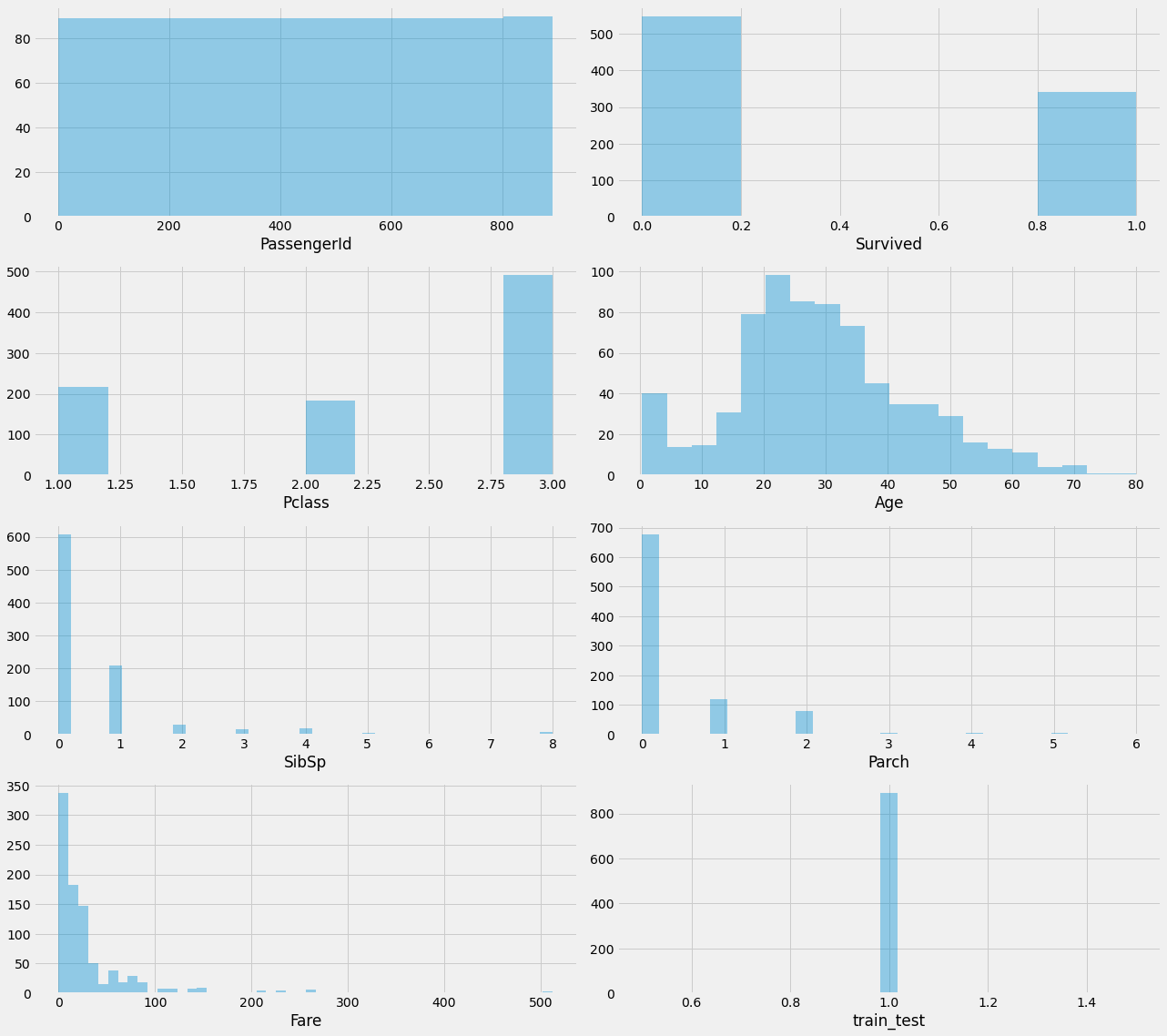
fig = plt.figure(figsize=(18,16))
for index, col in enumerate(numeric.columns):
plt.subplot(4,2,index+1)
sns.distplot(numeric.loc[:,col].dropna(), kde=False)
fig.tight_layout(pad=1.0)
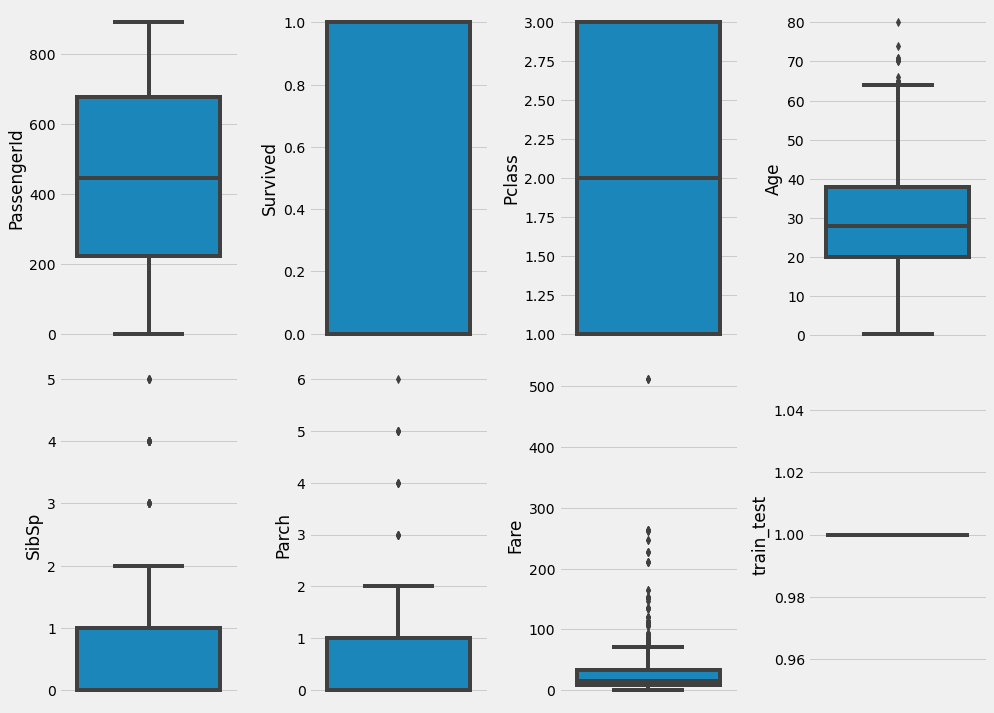
# Outliers
fig = plt.figure(figsize=(14,20))
for index , col in enumerate(numeric.columns):
plt.subplot(4,4, index+1)
sns.boxplot(y=col, data=numeric.dropna())
fig.tight_layout(pad=1.0)
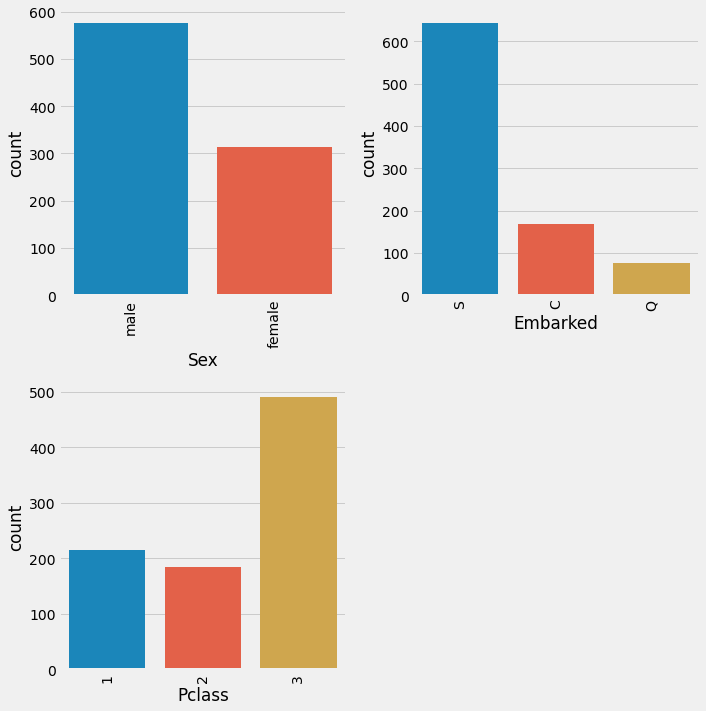
cat = train.select_dtypes(include=['object']).copy()
cat['Pclass'] = train['Pclass']
cat = cat.drop(['Ticket', 'Cabin', 'Name'], axis=1) #droped knowing it has a lot of possible values
cat.columns
Index(['Sex', 'Embarked', 'Pclass'], dtype='object')
fig = plt.figure(figsize=(10,20))
for index in range(len(cat.columns)):
plt.subplot(4,2,index+1)
sns.countplot(x=cat.iloc[:,index],data=cat.dropna())
plt.xticks(rotation=90)
fig.tight_layout(pad=1.0)
Transformation
df.isnull().sum().nlargest(40)
Cabin 1014
Survived 418
Age 263
Embarked 2
Fare 1
PassengerId 0
Pclass 0
Name 0
Sex 0
SibSp 0
Parch 0
Ticket 0
train_test 0
dtype: int64
df = df.drop(['Cabin'],axis=1)
#Filling missing Age values based on the median of the name tiltle (Mss. Mr. Mrs. etc)
import re
df['name_titles'] = df['Name'].apply(lambda x: re.findall(',\s(\w*).',x)[0])
df['Age'] = df.groupby('name_titles')['Age'].transform(lambda x: x.fillna(x.median()))
df['Embarked'] = df['Embarked'].fillna('S')
df['Embarked'].unique()
array(['S', 'C', 'Q'], dtype=object)
df['Fare'] = df.groupby('Pclass')['Fare'].transform(lambda x: x.fillna(x.mean()))
df.isnull().sum().nlargest(40)
Survived 418
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Embarked 0
train_test 0
name_titles 0
dtype: int64
df['fam'] = df['SibSp']+ df['Parch']
df = df.drop(['PassengerId', 'Name', 'Ticket', 'name_titles', 'Embarked', 'SibSp', 'Parch'], axis=1)
df
| Survived | Pclass | Sex | Age | Fare | train_test | fam | |
|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 3 | male | 22.0 | 7.2500 | 1 | 1 |
| 1 | 1.0 | 1 | female | 38.0 | 71.2833 | 1 | 1 |
| 2 | 1.0 | 3 | female | 26.0 | 7.9250 | 1 | 0 |
| 3 | 1.0 | 1 | female | 35.0 | 53.1000 | 1 | 1 |
| 4 | 0.0 | 3 | male | 35.0 | 8.0500 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 413 | NaN | 3 | male | 29.0 | 8.0500 | 0 | 0 |
| 414 | NaN | 1 | female | 39.0 | 108.9000 | 0 | 0 |
| 415 | NaN | 3 | male | 38.5 | 7.2500 | 0 | 0 |
| 416 | NaN | 3 | male | 29.0 | 8.0500 | 0 | 0 |
| 417 | NaN | 3 | male | 4.0 | 22.3583 | 0 | 2 |
1309 rows × 7 columns
#converting Sex and Embarked into Binary
df['Sex'] = np.where(df['Sex']== 'female', 1,0)
df = pd.get_dummies(df, columns=['Sex'])
df
| Survived | Pclass | Age | Fare | train_test | fam | Sex_0 | Sex_1 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 3 | 22.0 | 7.2500 | 1 | 1 | 1 | 0 |
| 1 | 1.0 | 1 | 38.0 | 71.2833 | 1 | 1 | 0 | 1 |
| 2 | 1.0 | 3 | 26.0 | 7.9250 | 1 | 0 | 0 | 1 |
| 3 | 1.0 | 1 | 35.0 | 53.1000 | 1 | 1 | 0 | 1 |
| 4 | 0.0 | 3 | 35.0 | 8.0500 | 1 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 413 | NaN | 3 | 29.0 | 8.0500 | 0 | 0 | 1 | 0 |
| 414 | NaN | 1 | 39.0 | 108.9000 | 0 | 0 | 0 | 1 |
| 415 | NaN | 3 | 38.5 | 7.2500 | 0 | 0 | 1 | 0 |
| 416 | NaN | 3 | 29.0 | 8.0500 | 0 | 0 | 1 | 0 |
| 417 | NaN | 3 | 4.0 | 22.3583 | 0 | 2 | 1 | 0 |
1309 rows × 8 columns
dfbin = df.copy()
dfbin['Fare'] = pd.qcut(dfbin['Fare'], 5)
dfbin = pd.get_dummies(dfbin, columns=['Fare', 'Pclass', 'fam'])
dfbin
| Survived | Age | train_test | Sex_0 | Sex_1 | Fare_(-0.001, 7.854] | Fare_(7.854, 10.5] | Fare_(10.5, 21.558] | Fare_(21.558, 41.579] | Fare_(41.579, 512.329] | ... | Pclass_3 | fam_0 | fam_1 | fam_2 | fam_3 | fam_4 | fam_5 | fam_6 | fam_7 | fam_10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 22.0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1.0 | 38.0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1.0 | 26.0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1.0 | 35.0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0.0 | 35.0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 413 | NaN | 29.0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 414 | NaN | 39.0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 415 | NaN | 38.5 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 416 | NaN | 29.0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | ... | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 417 | NaN | 4.0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
1309 rows × 22 columns
# Separating Train and Test
train_df = df[df['train_test']==1]
test_df = df[df['train_test']==0]
train_df = train_df.drop('train_test', axis=1)
test_df = test_df.drop('train_test', axis=1)
train_dfbin = dfbin[dfbin['train_test']==1]
test_dfbin = dfbin[dfbin['train_test']==0]
train_dfbin = train_dfbin.drop('train_test', axis=1)
test_dfbin = test_dfbin.drop('train_test', axis=1)
Fitting the model
train_dfbin_y = train_dfbin.Survived
train_dfbin_X = train_dfbin.drop(['Survived'], axis=1)
train_df_y = train_df.Survived
train_df_X = train_df.drop(['Survived'], axis=1)
train_df_X
| Pclass | Age | Fare | fam | Sex_0 | Sex_1 | |
|---|---|---|---|---|---|---|
| 0 | 3 | 22.0 | 7.2500 | 1 | 1 | 0 |
| 1 | 1 | 38.0 | 71.2833 | 1 | 0 | 1 |
| 2 | 3 | 26.0 | 7.9250 | 0 | 0 | 1 |
| 3 | 1 | 35.0 | 53.1000 | 1 | 0 | 1 |
| 4 | 3 | 35.0 | 8.0500 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... |
| 886 | 2 | 27.0 | 13.0000 | 0 | 1 | 0 |
| 887 | 1 | 19.0 | 30.0000 | 0 | 0 | 1 |
| 888 | 3 | 22.0 | 23.4500 | 3 | 0 | 1 |
| 889 | 1 | 26.0 | 30.0000 | 0 | 1 | 0 |
| 890 | 3 | 32.0 | 7.7500 | 0 | 1 | 0 |
891 rows × 6 columns
from sklearn.ensemble import GradientBoostingClassifier
from sklearn import model_selection, metrics
model = GradientBoostingClassifier().fit(train_df_X, train_df_y)
accuracy = round(model.score(train_df_X,train_df_y)*100,2)
cross_val = model_selection.cross_val_predict(GradientBoostingClassifier(n_estimators=150, learning_rate=0.1), train_df_X,train_df_y, cv=10, n_jobs=-1)
acc_cv = round(metrics.accuracy_score(train_df_y,cross_val)*100,2)
feature_ranks = pd.Series((model.feature_importances_)*100, index=train_df_X.columns).sort_values(ascending=False)
print('Acc ',accuracy )
print()
print('Cross val ', acc_cv)
print('Feature rank ')
print(feature_ranks)
Acc 89.67
Cross val 84.62
Feature rank
Sex_1 24.076661
Sex_0 22.933807
Fare 17.025432
Pclass 14.650911
Age 12.053696
fam 9.259494
dtype: float64
Cross Validation (using different models)
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
import math, time, random, datetime
train = pd.read_csv('titanic/train.csv')
test = pd.read_csv('titanic/test.csv')
train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
df_bin =pd.DataFrame() #to store continuous variables in bins ex(age bins: 0-10, 11-20, 21-31, etc..)
df_con = pd.DataFrame() # to store continuous variables
train.dtypes
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age float64
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
train.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 891.000000 | 891.000000 | 891.000000 | 714.000000 | 891.000000 | 891.000000 | 891.000000 |
| mean | 446.000000 | 0.383838 | 2.308642 | 29.699118 | 0.523008 | 0.381594 | 32.204208 |
| std | 257.353842 | 0.486592 | 0.836071 | 14.526497 | 1.102743 | 0.806057 | 49.693429 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.420000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 223.500000 | 0.000000 | 2.000000 | 20.125000 | 0.000000 | 0.000000 | 7.910400 |
| 50% | 446.000000 | 0.000000 | 3.000000 | 28.000000 | 0.000000 | 0.000000 | 14.454200 |
| 75% | 668.500000 | 1.000000 | 3.000000 | 38.000000 | 1.000000 | 0.000000 | 31.000000 |
| max | 891.000000 | 1.000000 | 3.000000 | 80.000000 | 8.000000 | 6.000000 | 512.329200 |
fig = plt.figure(figsize=(20,1))
sns.countplot(y='Survived', data=train)
print(train.Survived.value_counts())
0 549
1 342
Name: Survived, dtype: int64

df_bin['Survived']= train['Survived']
df_con['Survived']= train['Survived']
#Name ticket and Cabin have too many value types, hard to put in bins not so useful.
print(train.Name.value_counts().count())
print(train.Ticket.value_counts().count())
print(train.Cabin.value_counts().count())
891
681
147
sns.distplot(train.Pclass) # its Ordinal Data
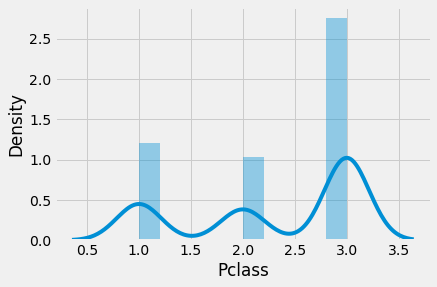
df_bin['Pclass']= train['Pclass']
df_con['Pclass']= train['Pclass']
plt.figure(figsize=(20,1))
sns.countplot(y='Sex', data=train)
<AxesSubplot:xlabel='count', ylabel='Sex'>

# Function to plot a count and a distribution(vs Survived) of each variable
def plot_count_dist (data, bin_df, label_column, target_colum, figsize=(20,5), use_bin_fd=False):
if use_bin_fd:
fig= plt.figure(figsize=figsize)
plt.subplot(1,2,1)
sns.countplot(y=target_colum, data=bin_df)
plt.subplot(1,2,2)
sns.distplot(data.loc[data[label_column]==1][target_colum], kde_kws={'label':'Survived'})
sns.distplot(data.loc[data[label_column]==0][target_colum], kde_kws={'label':'Did Not Survived'})
else:
fig= plt.figure(figsize=figsize)
plt.subplot(1,2,1)
sns.countplot(y=target_colum, data=data)
plt.subplot(1,2,2)
sns.distplot(data.loc[data[label_column]==1][target_colum], kde_kws={'label':'Survived'})
sns.distplot(data.loc[data[label_column]==0][target_colum], kde_kws={'label':'Did Not Survived'})
# Adding Sex and changing to binary form using np.where
df_bin['Sex'] = train['Sex']
df_bin['Sex'] = np.where(df_bin['Sex']== 'female', 1,0)
df_con['Sex'] = train['Sex']
# Adding SibSp = num of Siblings/Spouse
df_bin['SibSp']= train['SibSp']
df_con['SibSp']= train['SibSp']
plot_count_dist(train, bin_df=df_bin, label_column='Survived', target_colum='SibSp', figsize=(20,10))
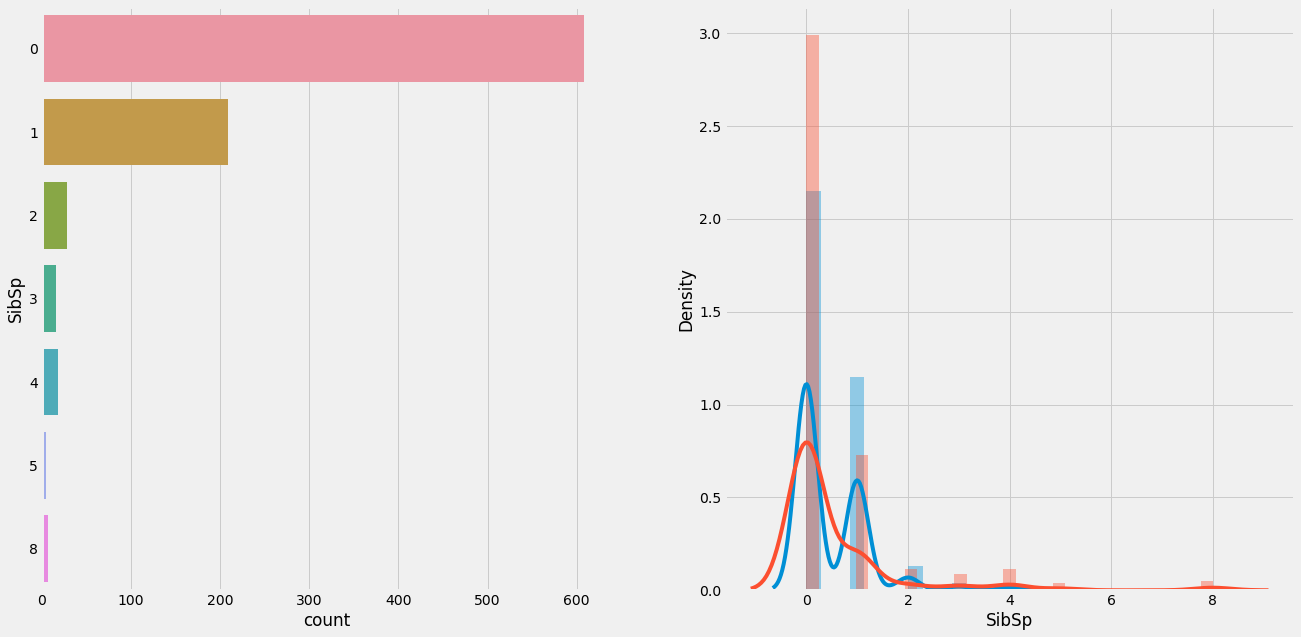
# Adding Parch = num of Parents/Children
df_bin['Parch']= train['Parch']
df_con['Parch']= train['Parch']
plot_count_dist(train, bin_df=df_bin, label_column='Survived', target_colum='Parch', figsize=(20,10))
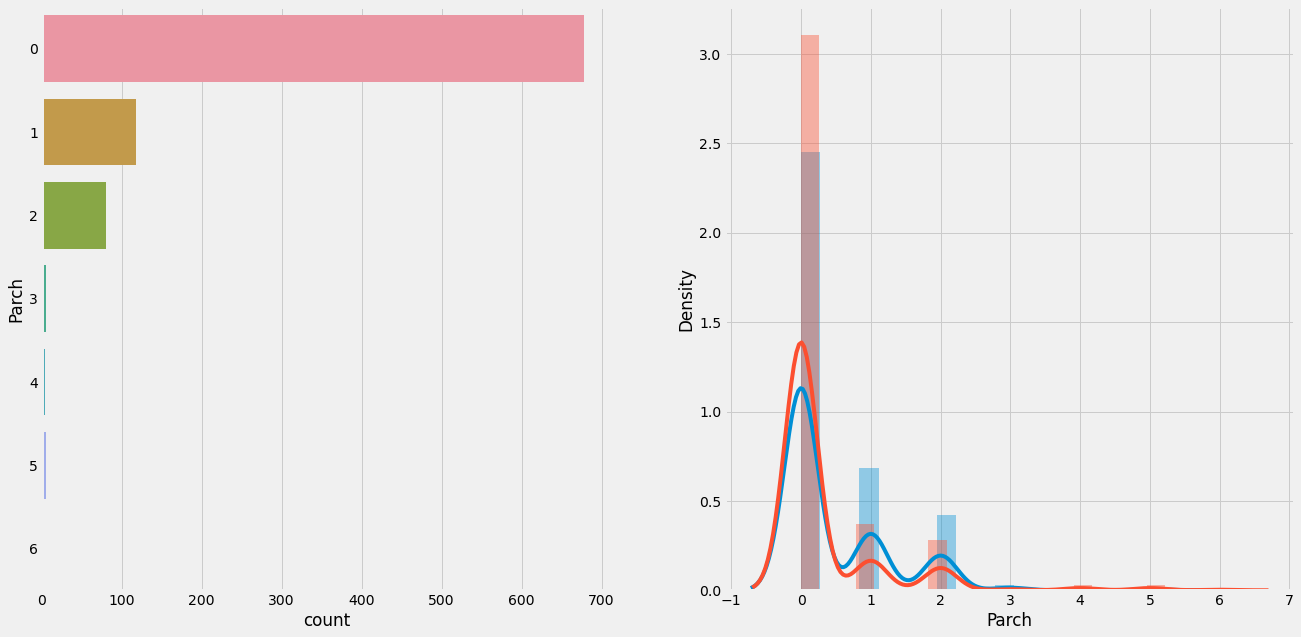
# Ading Fare, first variable to be cut into bins
df_con['Fare'] = train['Fare']
df_bin['Fare'] = pd.qcut(train['Fare'], 5)
plot_count_dist(train,df_bin,'Survived', 'Fare', use_bin_fd=True, figsize=(20,15))
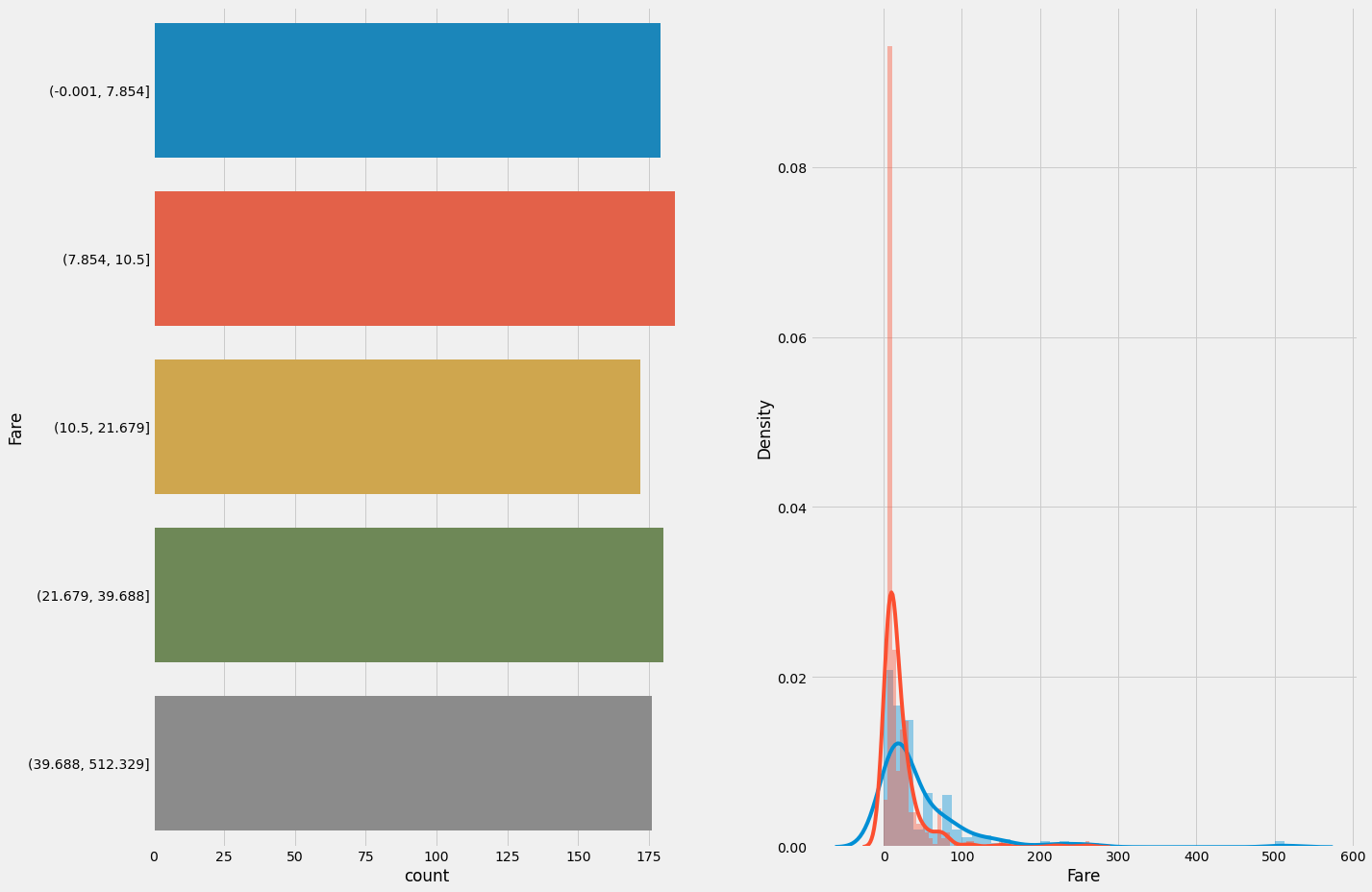
# Embarqued
df_bin['Embarked'] = train['Embarked']
df_con['Embarked'] = train['Embarked']
df_bin = df_bin.dropna(subset=['Embarked'])
df_con = df_con.dropna(subset=['Embarked'])
import re
df_con['name_titles'] = train['Name'].apply(lambda x: re.findall(',\s(\w*).',x)[0])
df_con['Age'] = train['Age']
df_con['Age'] = df_con.groupby('name_titles')['Age'].transform(lambda x: x.fillna(x.median()))
Feature Encoding
df_bin.head(20)
| Survived | Pclass | Sex | SibSp | Parch | Fare | Embarked | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 0 | 1 | 0 | (-0.001, 7.854] | S |
| 1 | 1 | 1 | 1 | 1 | 0 | (39.688, 512.329] | C |
| 2 | 1 | 3 | 1 | 0 | 0 | (7.854, 10.5] | S |
| 3 | 1 | 1 | 1 | 1 | 0 | (39.688, 512.329] | S |
| 4 | 0 | 3 | 0 | 0 | 0 | (7.854, 10.5] | S |
| 5 | 0 | 3 | 0 | 0 | 0 | (7.854, 10.5] | Q |
| 6 | 0 | 1 | 0 | 0 | 0 | (39.688, 512.329] | S |
| 7 | 0 | 3 | 0 | 3 | 1 | (10.5, 21.679] | S |
| 8 | 1 | 3 | 1 | 0 | 2 | (10.5, 21.679] | S |
| 9 | 1 | 2 | 1 | 1 | 0 | (21.679, 39.688] | C |
| 10 | 1 | 3 | 1 | 1 | 1 | (10.5, 21.679] | S |
| 11 | 1 | 1 | 1 | 0 | 0 | (21.679, 39.688] | S |
| 12 | 0 | 3 | 0 | 0 | 0 | (7.854, 10.5] | S |
| 13 | 0 | 3 | 0 | 1 | 5 | (21.679, 39.688] | S |
| 14 | 0 | 3 | 1 | 0 | 0 | (-0.001, 7.854] | S |
| 15 | 1 | 2 | 1 | 0 | 0 | (10.5, 21.679] | S |
| 16 | 0 | 3 | 0 | 4 | 1 | (21.679, 39.688] | Q |
| 17 | 1 | 2 | 0 | 0 | 0 | (10.5, 21.679] | S |
| 18 | 0 | 3 | 1 | 1 | 0 | (10.5, 21.679] | S |
| 19 | 1 | 3 | 1 | 0 | 0 | (-0.001, 7.854] | C |
from sklearn.preprocessing import OneHotEncoder, LabelEncoder, label_binarize
#df_bin.drop('Survived', axis=1, inplace=True)
df_bin_enc = pd.get_dummies(df_bin, columns=['Pclass', 'Sex', 'SibSp', 'Parch', 'Fare', 'Embarked'])
df_bin_enc
| Survived | Pclass_1 | Pclass_2 | Pclass_3 | Sex_0 | Sex_1 | SibSp_0 | SibSp_1 | SibSp_2 | SibSp_3 | ... | Parch_5 | Parch_6 | Fare_(-0.001, 7.854] | Fare_(7.854, 10.5] | Fare_(10.5, 21.679] | Fare_(21.679, 39.688] | Fare_(39.688, 512.329] | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
| 2 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 3 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
| 887 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 888 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 889 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 |
| 890 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | ... | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
889 rows × 28 columns
df_con_enc = pd.get_dummies(df_con, columns=['Sex', 'Embarked'])
df_con_enc
| Survived | Pclass | SibSp | Parch | Fare | name_titles | Age | Sex_female | Sex_male | Embarked_C | Embarked_Q | Embarked_S | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | 1 | 0 | 7.2500 | Mr | 22.0 | 0 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 0 | 71.2833 | Mrs | 38.0 | 1 | 0 | 1 | 0 | 0 |
| 2 | 1 | 3 | 0 | 0 | 7.9250 | Miss | 26.0 | 1 | 0 | 0 | 0 | 1 |
| 3 | 1 | 1 | 1 | 0 | 53.1000 | Mrs | 35.0 | 1 | 0 | 0 | 0 | 1 |
| 4 | 0 | 3 | 0 | 0 | 8.0500 | Mr | 35.0 | 0 | 1 | 0 | 0 | 1 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 0 | 2 | 0 | 0 | 13.0000 | Rev | 27.0 | 0 | 1 | 0 | 0 | 1 |
| 887 | 1 | 1 | 0 | 0 | 30.0000 | Miss | 19.0 | 1 | 0 | 0 | 0 | 1 |
| 888 | 0 | 3 | 1 | 2 | 23.4500 | Miss | 21.0 | 1 | 0 | 0 | 0 | 1 |
| 889 | 1 | 1 | 0 | 0 | 30.0000 | Mr | 26.0 | 0 | 1 | 1 | 0 | 0 |
| 890 | 0 | 3 | 0 | 0 | 7.7500 | Mr | 32.0 | 0 | 1 | 0 | 1 | 0 |
889 rows × 12 columns
Building Models 🙆🏽♂️
X_train_bin = df_bin_enc.drop('Survived', axis=1)
y_train_bin = df_bin_enc.Survived
X_train_con = df_con_enc.drop(['Survived','name_titles'], axis=1)
y_train_con = df_con_enc.Survived
from sklearn import model_selection, metrics
from sklearn.svm import LinearSVC
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.linear_model import LinearRegression, LogisticRegression, SGDClassifier
from sklearn.tree import DecisionTreeClassifier
# Function to run different algorithm with cross val
def fit_algo(algo, X_train, y_train, cv): #cv Cross validate, number of times try 10
model = algo.fit(X_train, y_train)
accuracy = round(model.score(X_train,y_train)*100,2)
cross_val = model_selection.cross_val_predict(algo, X_train,y_train, cv=cv, n_jobs=-1)
acc_cv = round(metrics.accuracy_score(y_train,cross_val)*100,2)
#feature_ranks = pd.Series((model.feature_importances_)*100, index=X_train.columns).sort_values(ascending=False)
return accuracy, acc_cv, #feature_ranks
TOP Performing Algorithms
acc_grad_boost, cross_grad_boost, featureranks = fit_algo(GradientBoostingClassifier(n_estimators=300, learning_rate=0.1), X_train_con, y_train_con,10)
print('General Acc is ' , acc_grad_boost)
print()
print('With cross val is ',cross_grad_boost)
print()
print(featureranks)
General Acc is 94.94
With cross val is 84.03
Sex_female 22.476185
Fare 21.774555
Sex_male 17.517075
Age 16.592819
Pclass 12.358341
SibSp 5.821414
Embarked_S 1.495644
Parch 1.172607
Embarked_Q 0.420607
Embarked_C 0.370754
dtype: float64
acc_dTree, cross_dTree = fit_algo( DecisionTreeClassifier(), X_train_con, y_train_con, 10)
print('General Acc is ' , acc_dTree)
print()
print('With cross val is ',cross_dTree)
General Acc is 97.86
With cross val is 76.15
Worst Performing Algorithms
accuracy_LSVC, Cross_LSVC =fit_algo(LinearSVC(), X_train_bin, y_train_bin, 10)
print('General Acc is ' , accuracy_LSVC)
print()
print('With cross val is ',Cross_LSVC)
General Acc is 80.2
With cross val is 78.85
acc_log, cross_log = fit_algo( LogisticRegression(), X_train_bin, y_train_bin, 10)
print('General Acc is ' , acc_log)
print()
print('With cross val is ',cross_log)
General Acc is 79.64
With cross val is 78.85
acc_KN, cross_KN = fit_algo(KNeighborsClassifier(), X_train_bin, y_train_bin, 10)
print('General Acc is ' , acc_KN)
print()
print('With cross val is ',cross_KN)
General Acc is 82.45
With cross val is 78.29
acc_gaus, cross_gaus = fit_algo(GaussianNB(), X_train_con, y_train_con, 10)
print('General Acc is ' , acc_gaus)
print()
print('With cross val is ',cross_gaus)
General Acc is 79.08
With cross val is 78.52
acc_sgdc, cross_sgdc = fit_algo(SGDClassifier(), X_train_bin, y_train_bin, 10)
print('General Acc is ' , acc_sgdc)
print()
print('With cross val is ',cross_sgdc)
General Acc is 80.2
With cross val is 77.28
from sklearn.svm import SVC, NuSVC
acc_grad_boost, cross_grad_boost = fit_algo(NuSVC(), X_train_bin, y_train_bin,10)
print('General Acc is ' , acc_grad_boost)
print()
print('With cross val is ',cross_grad_boost)
General Acc is 81.55
With cross val is 80.88